
Node.js 模块系统 -- CommonJS
模块是应用程序的构建的基础。它允许将代码划分为可独立开发和测试的小单元。使用模块也可强制隐藏一些信息,将一些函数或变量保持为私有。
目前 Node.js 有两种不同的模块系统:
CommonJSECMAScript modules(ESM)
为什么需要模块系统?
一个好的模块系统可以帮助解决许多软件工程的基本需求:
- 通过模块可将代码拆分为多个文件。 使代码容易理解,更易于组织。同时可以独立的开发和测试小的单元模块。
- 方便代码在不同的项目中重用。
- 方便封装和隐藏一些私用功能、变量。
- 管理依赖项。 一个好的模块系统能够方便开发者在现有的模块上构建新的模块。模块系统还应该使模块用户能够轻松地导入给定模块运行所必需的依赖链(瞬态依赖)。
JavaScript 和 Node.js 中的模块系统?
在很长一段时间里,JavaScript 中是没有内置的模块系统的。一般都是通过 <script> 标签来引入不同的文件。
随着 JavaScript 的发展,社区提出了几个可以在 JavaScript 中使用的模块系统。例如 AMD 和 UMD。
Node.js 被创建的时候,提出了自己的模块系统规范 CommonJS。
到了 2015 年,随着 ECMAScript 6 (也叫 ES2015)的发布,JavaScript 终于有了一个标准模块系统的官方提案 — ESM。ECMAScript 6 仅在语法和语义方面定义了 ESM 的正式规范,但没有提供任何实现细节。不同的浏览器公司和 Node.js 社区花了好几年的时间才提出了这个规范的可靠实现。Node.js 从 13.2 版开始就提供了对 ESM 的稳定支持。
揭示模块模式
在讨论 CommonJS 之前,先了解一个设计模式 — 揭示模块模式(The Revealing Module Pattern)。它允许你定义一个自包含的模块,其中只暴露出外部需要访问的部分,而将实现细节隐藏在内部。
const myModule = (() => {
const privateFoo = () => {}
const privateBar = []
const exported = {
publicFoo: () => {},
publicBar: () => {}
}
return exported
})()该模式使用了一个自调用函数(IIFE)。它创建了一个私有作用域,只导出需要公共访问的部分。
这个模式背后的思想被用作 CommonJS 模块系统的实现基础。
CommonJS 模块系统
CommonJS 是第一个内置在 Node.js 中的模块系统。Node.js 的 CommonJS 实现遵循CommonJS 规范,并添加了一些自定义扩展。
CommonJS 规范的两个主要概念:
require函数,允许从本地文件系统导入模块;exports和module.exports两个特殊变量允许从当前模块中导出公开的功能;
自定义一个模块加载器
从头构建一个类似 CommonJS 的模块系统。下面的代码模拟 require 函数的部分功能。
定义 loadModule 函数,加载模块的内容,将其包装到私有作用域,并对其求值:
function loadModule (filename, module, require) {
const wrappedSrc = `(function (module, exports, require) {
${fs.readFileSync(filename, 'utf8')}
})(module, module.exports, require)`
eval(wrappedSrc)
}一个模块的源代码实际上被包裹到了一个函数中,和揭示模块模式一样。需要注意包装函数的 exports 使用的是 module.exports 。另外,读取模块文件内容使用的是同步的方法,这能能够按顺序的加载多个模块。
接下来实现 require() 函数。
function require (moduleName) {
console.log(`Require invoked for module: ${moduleName}`)
const id = require.resolve(moduleName) // 1
if (require.cache[id]) { // 2
return require.cache[id].exports
}
// module metadata
const module = { // 3
exports: {},
id: id
}
// Update the cache
require.cache[id] = module // 4
// load the module
loadModule(id, module, require) // 5
return module.exports // 6
}
require.cache = {}
require.resolve = (moduleName) => {
/* resolve a full module id from the moduleName */
}- 模块名作为输入,第一步就是要解析模块路径作为
id。通过require.resolve函数进行处理。 - 如果模块已经加载过,那么在缓存中存在,直接返回。
- 如果没有加载过,那么是第一次加载的环境。创建一个新的
module对象,包含对应 的id和空的exports属性。 - 缓存这个新的
module对象。 - 调用
loadModule函数从文件中加载模块源代码并执行。在模块的代码中会通过module.exports来暴露公共 API,此时就替换了空的exports对象。 - 最后返回
module.exports,暴露出公共 API。
定义一个模块
下面是一个定义一个模块的例子:
const dependency = require('./anotherModule')
function log() {
console.log(`Well done ${dependency.username}`)
}
module.exports.run = () => {
log()
}理解 module.exports 和 exports
从上面的 loadModule 函数中可以看出,exports 是对 module.exports 初始值的引用。这个初始值是在模块加载前创建的空对象。
这意味着我们只能将新属性附加到 exports 变量引用的对象上,如下面的代码所示:
exports.hello = () => {
console.log('Hello')
}如果给 exports 变量重新赋值,那么将不会导出,因为没有改变 module.exports 对象。
如果想要导出的不是对象,例如想要导出函数或一个实例。那么需要修改 module.exports 。
module.exports = () => {
console.log("hello")
}require 函数是同步的
上面自定义的 require 函数是同步的,并且 Node.js 自带的也是同步的。因此,对于 module.exports 的任何赋值和导出都需要是同步的。
模块解析算法
模块解析算法的实现,也就是 module.resolve() 函数。
首先了解一下依赖地狱:一个程序的两个或多个依赖项依次依赖于一个共享依赖项,但需要不同的版本。Node.js 根据模块的加载位置不同来加载不同的模块,通过这种方式解决这个问题。该特性的归功于 Node.js 包管理器(如 npm 或 yarn )组织应用程序依赖关系的方式,以及 require() 函数中使用的解析算法。
resolve() 接收模块名称,并返回模块的完整路径,通过这个路径唯一标识该模块。解析算法可以分为如下三个分支:
- 文件模块。 如果模块名称是以
/开始的,表示绝对路径,直接返回即可。如果是./开头,表示相对路径,需要从需要的模块开始计算出路径。 - 核心模块。 如果没有
/和./,那么首先从 Node.js 自带的核心库查找。 - 软件包模块。 如果没有找到匹配的核心模块,则继续搜索,在目录结构中从需要的模块开始向上导航的第一个
node_modules目录中查找匹配的模块。然后依次向上查找node_modules目录,直到到达根目录。
node_modules目录是包管理器用来安装每个软件包依赖的地方。
对于文件模块和软件包模块,文件和目录都可以用来匹配到模块名。实际上,算法会尝试匹配如下内容:
<moduleName>.js<moduleName>/index.js<moduleName>/package.js文件中的main属性指定的目录或文件
模块缓存
每个模块只在第一次需要时加载和求值,任何后续调用 require() 都会简单地返回缓存的版本。缓存对性能很重要,同时也有一些其他的好处:
- 解决了循环依赖的问题;
- 在一定程度上,它保证在从给定包中要求相同模块时总是返回相同的实例;
循环依赖
下面是一个循环依赖的例子。
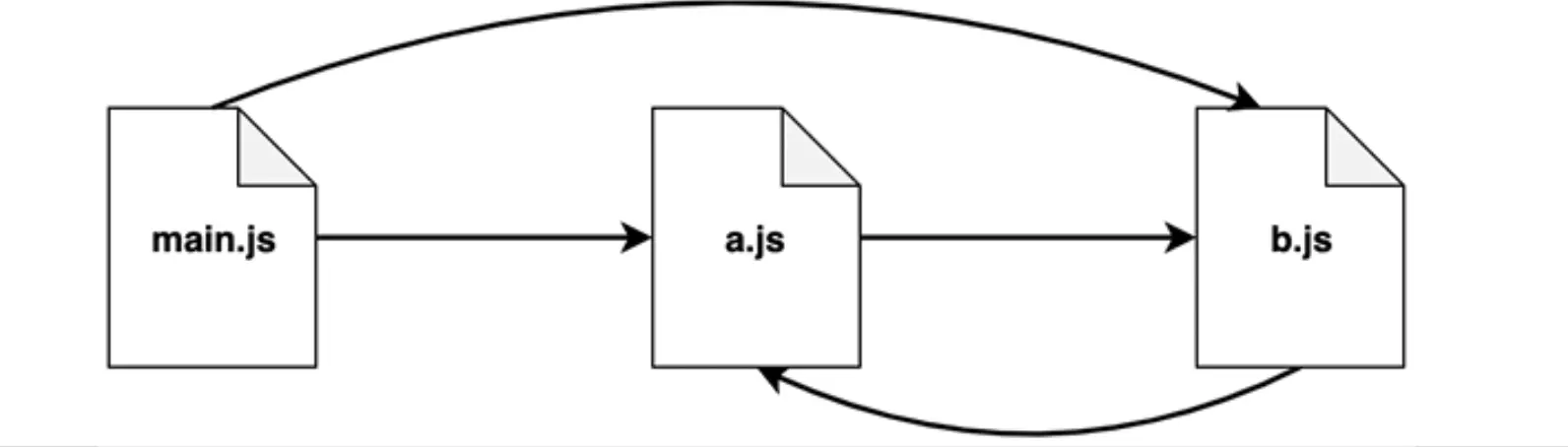
模块 a 的代码为:
exports.loaded = false
const b = require('./b.js')
module.exports = {
b,
loaded: true
}模块 b 的代码为:
exports.loaded = false
const a = require('./a.js')
module.exports = {
a,
loaded: true
}模块 main 的代码为:
const a = require('./a.js')
const b = require('./b.js')
console.log('a -> ', JSON.stringify(a, null, 2))
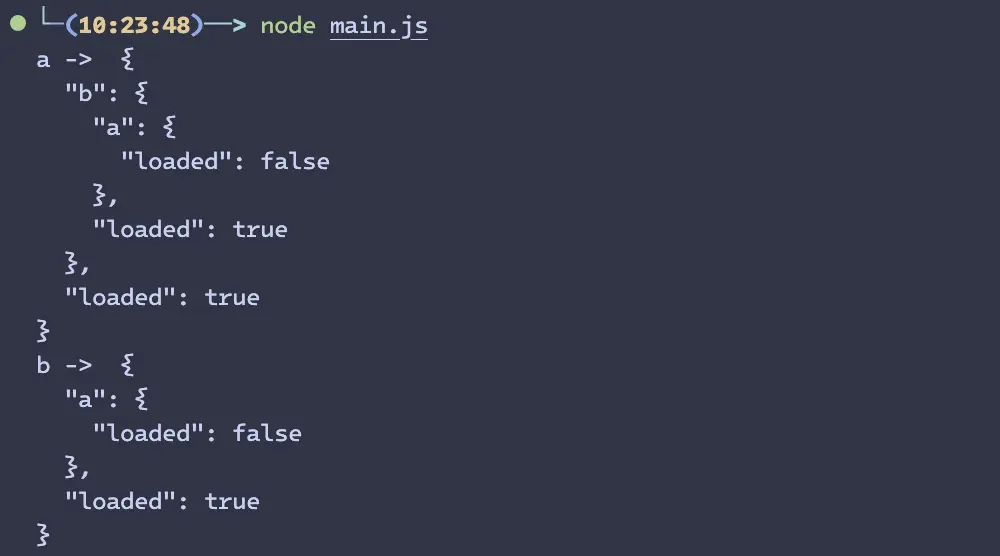
console.log('b -> ', JSON.stringify(b, null, 2))使用 node main.js 运行之后,打印的结果为:
下图是整个循环依赖的加载过程。
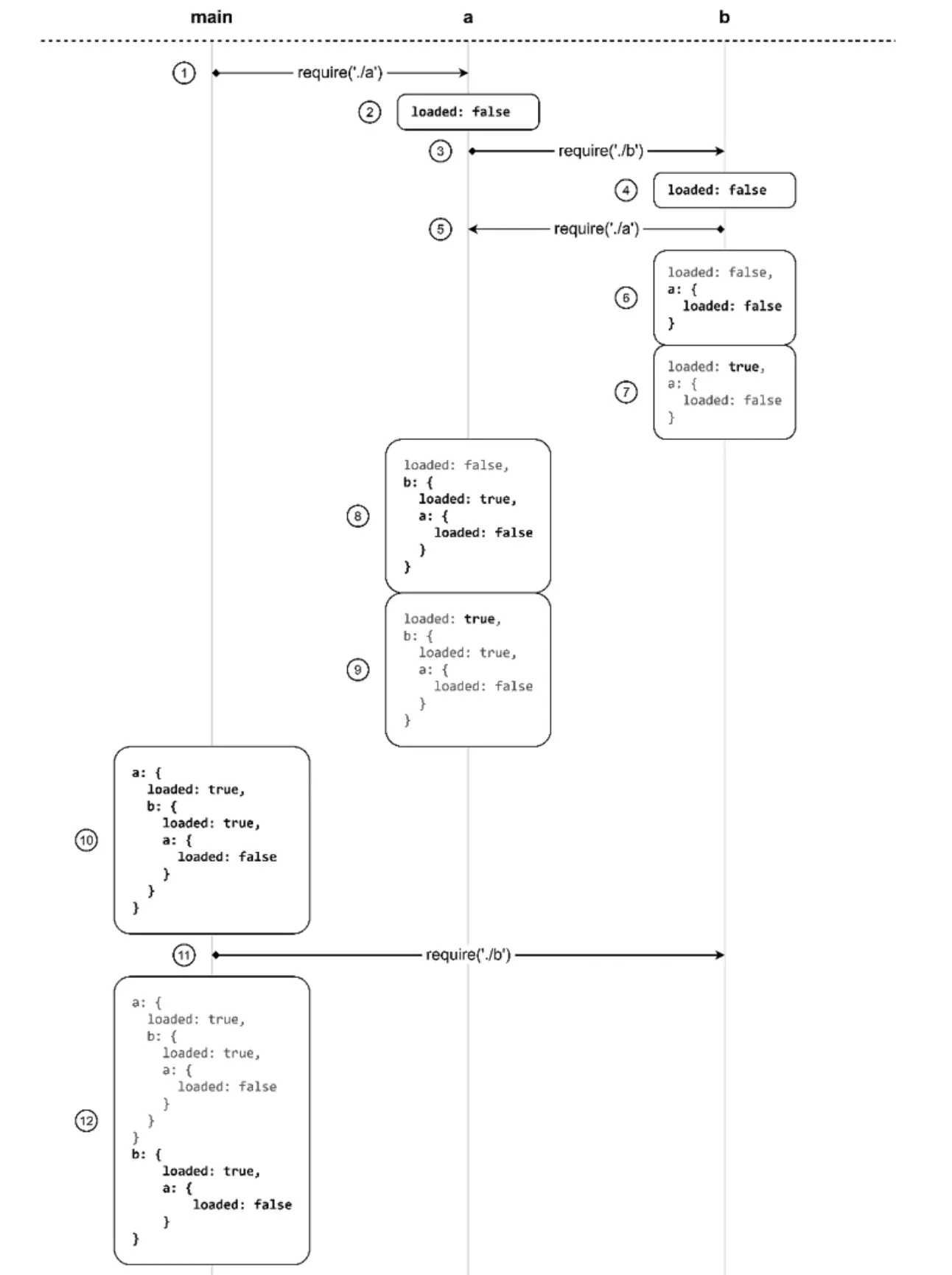
- 程序执行从
main.js开始,它会首先加载a.js。 - 模块
a首先暴露出了loaded属性,并将其设置为false。 - 接下来模块
a开始导入模块b。 - 和模块
a一样,模块b也是先导出loaded属性,并将其设置为false。 - 接下来模块
b需要导入模块a,此时,出现了循环依赖。 - 由于模块
a已经遍历过,所以导入时候,会直接返回缓存,此时a模块导出的是一个对象{ loaded: false }。 - 模块
b继续执行通过修改module.exports返回一个新的对象,此时将loaded属性设置为true,到此时,模块b导出的是一个对象{ a: {loaded: false}, loaded: true }。 - 此时
b模块已经执行完成,将控制权交还给a模块,并将b导出的对象赋值给了a模块中的b变量,也就是{ a: {loaded: false}, loaded: true }。 a模块的最后一步是通过module.exports导出一个新的对象,也就是{b: { a: {loaded: false}, loaded: true}, loaded: true}。- 此时,
a模块执行完成,将控制权交给main.js模块。 - 接下来
main模块加载b模块,由于b模块已经加载过,此时直接返回缓存,也就是{ a: {loaded: false}, loaded: true }。
模块定义语法
命名导出
// file logger.js
exports.info = (message) => {
console.log(`info: ${message}`)
}
exports.verbose = (message) => {
console.log(`verbose: ${message}`)
}
// file main.js
const logger = require('./logger')
logger.info('This is an informational message')
loger.verbose('This is a verbose message')导出函数
// file logger.js
module.exports = (message) => {
console.log(`info: ${message}`)
}
module.exports.verbose = (message) => {
console.log(`verbose: ${message}`)
}
// file main.js
const logger = require('./logger')
logger('This is an informational message')
logger.verbose('This is a verbose message')导出一个类
class Logger {
constructor (name) {
this.name = name
}
log (message) {
console.log(`[${this.name}] ${message}`)
}
info (message) {
this.log(`info: ${message}`)
}
verbose (message) {
this.log(`verbose: ${message}`)
}
}
module.exports = Logger导出一个实例
class Logger {
constructor (name) {
this.count = 0
this.name = name
}
log (message) {
this.count++
console.log('[' + this.name + '] ' + message)
}
}
module.exports = new Logger('DEFAULT')”因为模块是缓存的,每个需要日志模块的模块实际上总是检索相同实例,从而共享其状态。这种模式非常类似单例。然而,它不能保证实例在整个应用程序中的唯一性。在分析解析算法时,我们已经看到一个模块可能会在应用程序的依赖树中被安装多次。这将会创建相同逻辑模块的多个实例,所有实例都运行在同一个 Node.js 应用程序的上下文中。
修改一个模块
有时候可以通过模块来修改另一个模块。
// file patcher.js
require('./logger').customMessage = function() {
console.log('This is a new functionality')
}此时可使用 patcher 模块来修改 logger 模块为它添加 customMessage 方法。
// file main.js
require('./patcher.js')
const logger = require('./logger') // 由于在 patcher 模块已经加载过,再次使用的是修改过的缓存
logger.customMessage()